![]()
elevata® is an Architecture Runtime for modern data platforms.
It turns metadata into deterministic, executable data architecture. Architecture is defined declaratively and executed consistently across warehouses.
SQL becomes an artifact. Architecture becomes metadata.
The same metadata-defined architecture can be rendered, reviewed, and executed consistently on:
Snowflake · Databricks · Fabric · MSSQL · Postgres · DuckDB · BigQuery
without rewriting logic or introducing dialect-specific modeling.
elevata separates:
- Logical architecture
- Dialect rendering
- Execution backend
This makes data architecture portable, reproducible, governable, and auditable.
elevata is an Architecture Runtime for metadata-defined data platforms.
It models datasets, lineage, contracts, governance, and execution semantics as explicit metadata.
From these definitions, elevata derives deterministic logical plans, renders dialect-owned SQL, reviews architecture changes, and executes warehouse-native pipelines through controlled runtime scopes.
Schema evolution, incremental loads, historization, approvals, and execution evidence are planned, validated, and applied deterministically.
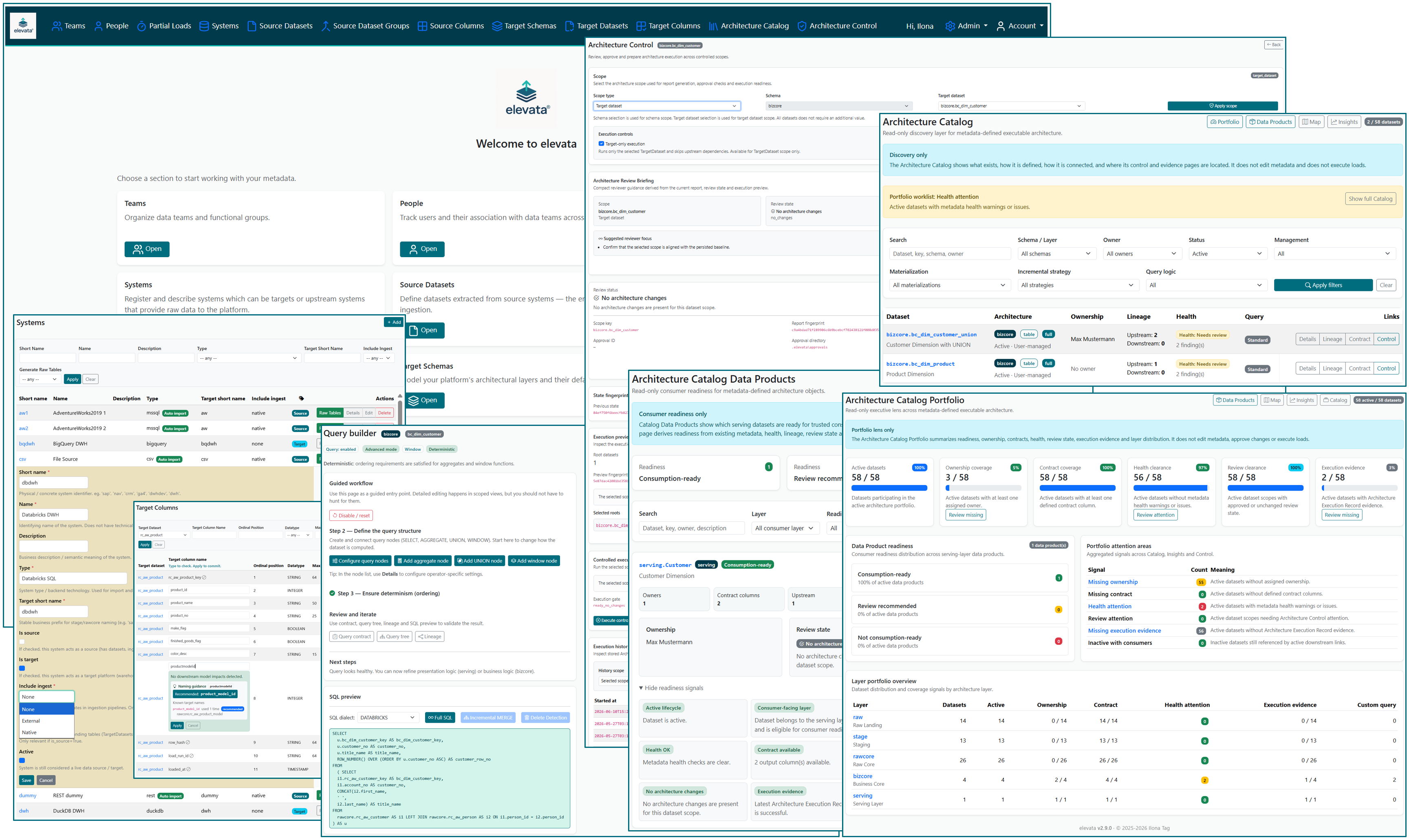
Architecture Runtime UI for discovering, controlling, modeling, and executing metadata-defined data architecture
Most data platforms encode architecture implicitly in SQL and pipeline code.
elevata makes architecture explicit.
- Metadata defines behavior.
- Dialects own SQL shape.
- Control makes changes reviewable and auditable.
- Execution is deterministic, observable, and evidence-based.
The result is governed, explainable, portable, and executable data architecture.
Modern data platforms often fail not because of missing tools, but because
architecture, lineage, and governance are encoded implicitly in SQL and pipeline code.
elevata exists to make these concerns explicit, declarative, and reproducible.
The Architecture Runtime concept behind elevata is described in the publication section:
These publications explain why modern data platforms need metadata-defined, deterministic, controllable, executable, and auditable architecture.
The core elevata execution pipeline consists of four explicitly separated layers:
- Metadata Model
- Deterministic Logical Plan
- Dialect Rendering
- Warehouse-Native Execution
Each layer is explicitly separated.
- Import or define source metadata, lineage, contracts, and execution semantics
- Review source metadata import outcomes before generation
- Discover architecture through Catalog, Data Products, Portfolio, Insights, and Maps
- Inspect generated SQL, lineage, contracts, health, and execution evidence
- Review architecture changes through Architecture Review Briefing and approve them through Architecture Control
- Execute approved or unchanged scopes deterministically on your target warehouse
- Audit execution through Architecture Execution Records
Pipelines are executed dataset-driven and lineage-aware.
Execution supports full and incremental loads, historization, schema evolution, and structured load logging.
Behavior is deterministic and observable.
Schema drift is reconciled through Architecture MigrationPlan-driven materialization:
renames, adds, type evolution and controlled rebuilds are derived from architecture state, while destructive changes remain explicitly policy-gated.
elevata makes source metadata import reviewable.
Metadata import results explain what was discovered across SQLAlchemy-backed systems, files and REST sources.
Instead of showing only that columns were processed, elevata distinguishes whether source columns were created, actually changed, unchanged, removed, or need manual review.
This gives users immediate confidence after import:
- Created columns are new in elevata metadata.
- Changed columns existed before and now differ from the previous technical metadata state.
- Unchanged columns were checked and still match the previous metadata state.
- Removed columns no longer exist in the imported source shape.
- PK columns show detected primary key candidates.
- Needs review highlights skipped datasets or unresolved metadata decisions.
The import review is deterministic, transient and read-only as a report. It does not introduce a new wizard, oes not persist import history, and does not change the existing source import semantics.
elevata provides a read-only Architecture Catalog for discovering metadata-defined executable architecture.
The Catalog shows what exists, how datasets are defined, how they are connected, how they are controlled, where execution evidence is available, how portfolio posture looks, and which architecture quality and governance signals need attention.
Users can search and filter TargetDatasets by schema, owner, lifecycle status, system-managed status, materialization type, incremental strategy and query logic.
Catalog detail pages summarize architecture metadata, ownership, health, upstream inputs, downstream consumers, column contract signals and the latest Architecture Execution Record for the dataset scope.
Catalog Portfolio summarizes architecture posture across readiness, ownership, contracts, health, review state, execution evidence and layer distribution. Actionable Portfolio KPIs open filtered Catalog worklists so users can inspect affected datasets before navigating to dataset detail or Architecture Control.
Catalog Data Products show which serving-layer datasets are ready for trusted consumption. Readiness is derived from ownership, metadata health, query contracts, lineage, Architecture Control review state and execution evidence.
Catalog Insights highlight ownership gaps, metadata health findings, custom query logic, downstream consumer visibility, inactive datasets with consumers, missing execution evidence, and dataset-specific Architecture Control review status summaries.
Catalog Maps show architecture across layers using layer cards, a layer flow overview, a source-to-target layer dependency matrix and expandable direct dependency examples.
The Catalog does not edit metadata and does not execute loads. Architecture Control remains responsible for approval, execution, execution records and retention workflows.
elevata makes architecture changes reviewable before execution.
Architecture State, Change Reports, Promotion Reports, Approval Artifacts and Execution Records expose deterministic fingerprints, MigrationPlan actions, policy decisions, review decisions and execution outcomes.
This supports controlled review, CI checks and environment-to-environment architecture promotion while keeping execution guardrails inside the load runner.
The Architecture Control UI makes approval state, scope, policy status, change summary, execution preview, dependency mode, captured output and execution records visible for controlled scopes.
Architecture Review Briefing adds compact reviewer guidance directly inside Architecture Control. It summarizes the selected scope, review state, change volume, policy attention, destructive or blocking signals, execution readiness and suggested reviewer focus before approval or execution.
Users can inspect reports, open the Review Briefing details on demand, download report JSON, create Approval Artifacts, verify approvals, execute approved or no-change scopes, inspect the resulting Architecture Execution Record, review stored execution history, download record JSON, and apply execution record retention.
elevata models transformations explicitly using Query Trees.
Each TargetDataset may define a query tree composed of well-defined operators such as SELECT, JOIN, AGGREGATE, UNION and WINDOW. These operators are represented as metadata objects, not as opaque SQL fragments.
The Query Builder produces deterministic SQL with stable contracts, field-level lineage, and transparent query semantics.
elevata supports deterministic Metadata Naming Guidance while editing TargetColumns.
Guidance is derived from existing column mappings and previously used target names. It helps modelers reuse project-specific naming decisions without AI, without a global dictionary and without enforcing naming rules.
For direct source inputs, elevata uses the technical SourceColumn name. For upstream target inputs, it uses the immediate upstream TargetColumn name, so guidance follows the current modeling step instead of tracing back to the original source-system field.
Naming Guidance focuses on rawcore and bizcore technical naming decisions. Serving-layer friendly names and historized rawcore datasets are excluded from recommendation evidence.
Recommended names can be applied directly from the TargetColumn inline editor, but they remain advisory. Existing validation, collision checks and rename handling stay authoritative.
elevata evolves along four strategic axes:
1. Architecture Catalog & Portfolio
Making executable architecture discoverable across datasets, lineage, contracts, ownership, readiness, health, and execution evidence.
2. Architecture Control & Auditability
Strengthening review briefing, approval, execution evidence, promotion, retention, and controlled runtime operation.
3. Source Abstraction & Ingestion
Expanding source patterns such as files, APIs, cloud transports, federated access and reviewable metadata import while preserving deterministic RAW and Stage semantics.
4. Runtime Hardening & Execution Semantics
Improving backend coverage, dialect behavior, schema evolution safety, and reproducible execution across supported warehouses.
See /docs for architectural depth.
For a deeper architectural and strategic overview of elevata’s direction, see the elevata Platform Strategy.
elevata itself does not require personal data.
If used with customer datasets, responsibility for compliance remains with the implementing organisation.
The system supports pseudo-key hashing and consistent pseudonymisation-oriented strategies via its hashing DSL.
This project is an independent open-source initiative.
- It is not a consulting service.
- It is not a customer project.
- It does not store or process customer data.
- It is not in competition with any company.
The purpose of elevata is to contribute to the community by providing an Architecture Runtime for metadata-defined data platforms.
The project is published under the AGPL v3 license and open for use by any organization.
© 2025-2026 Ilona Tag - All rights reserved.
elevata® is an open-source software project for metadata-defined data architecture.
elevata® is a registered trademark in Germany.
Other product names, logos, and brands mentioned here are property of their respective owners.
Released under the GNU Affero General Public License v3 (AGPL-3.0).
See LICENSE for terms and NOTICE.md for third-party license information.